QR codes are a near-ubiquitous type of barcode designed to be scanned by ordinary cameras. In my various fieldwork campaigns, we used QR codes to link images with metadata and sample identity, enabling field-to-result tracking of individuals. However, like most parts of fieldwork, taking these images rarely goes to plan: we often find the images taken in the field have comparatively low rates of QR code decoding with common open source libraries.
In this post, I document my recent work trying to improve the rate at which QR codes are recognised in these images from the field. TL;DR: with a few very simple and automated image manipulations (scaling, sharpening, and blurring), we can dramatically improve the rate at which barcodes can be recognised. If you are interested in using these methods, please see https://qrmagic.kdmurray.id.au/, and/or the NVTK.
Field images
First, let’s see a collection of images from the field. These examples were taken during several different field campaigns I’ve been involved in over the last several years. We use these images to take visual note of the appearance of plants we collect. As much of our work (e.g. DNA extraction) destroys the sample we have taken, we need some way to see what the plant (or leaf, flower, seed capsule etc) we collected actually looked like in the field. We also often take notes alongside the image, tying the sample’s ID to, e.g., date, location, etc. In case of a metadata mixup, we can later check these images to confirm the correct particulars as they were recorded in the field.



















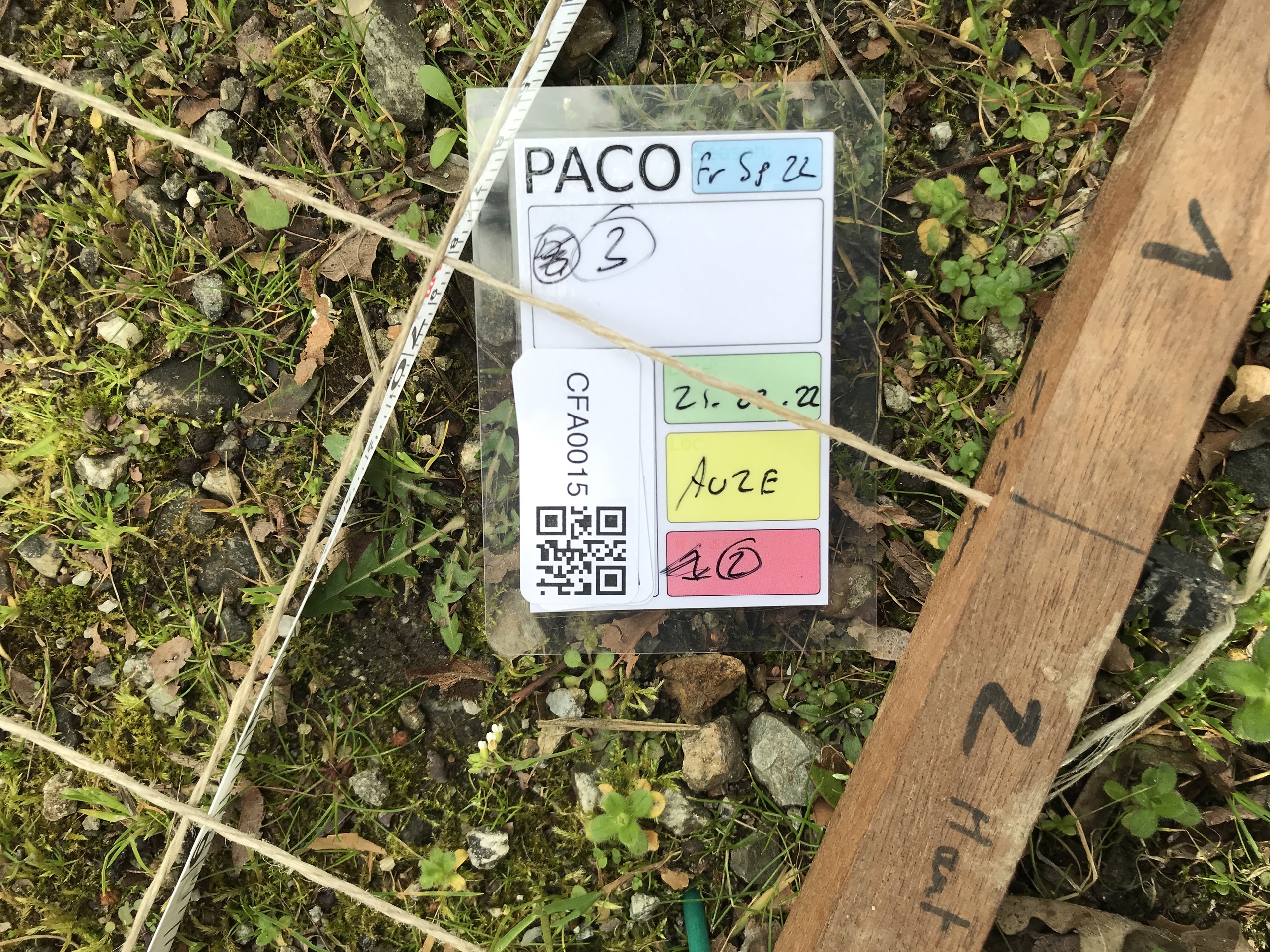
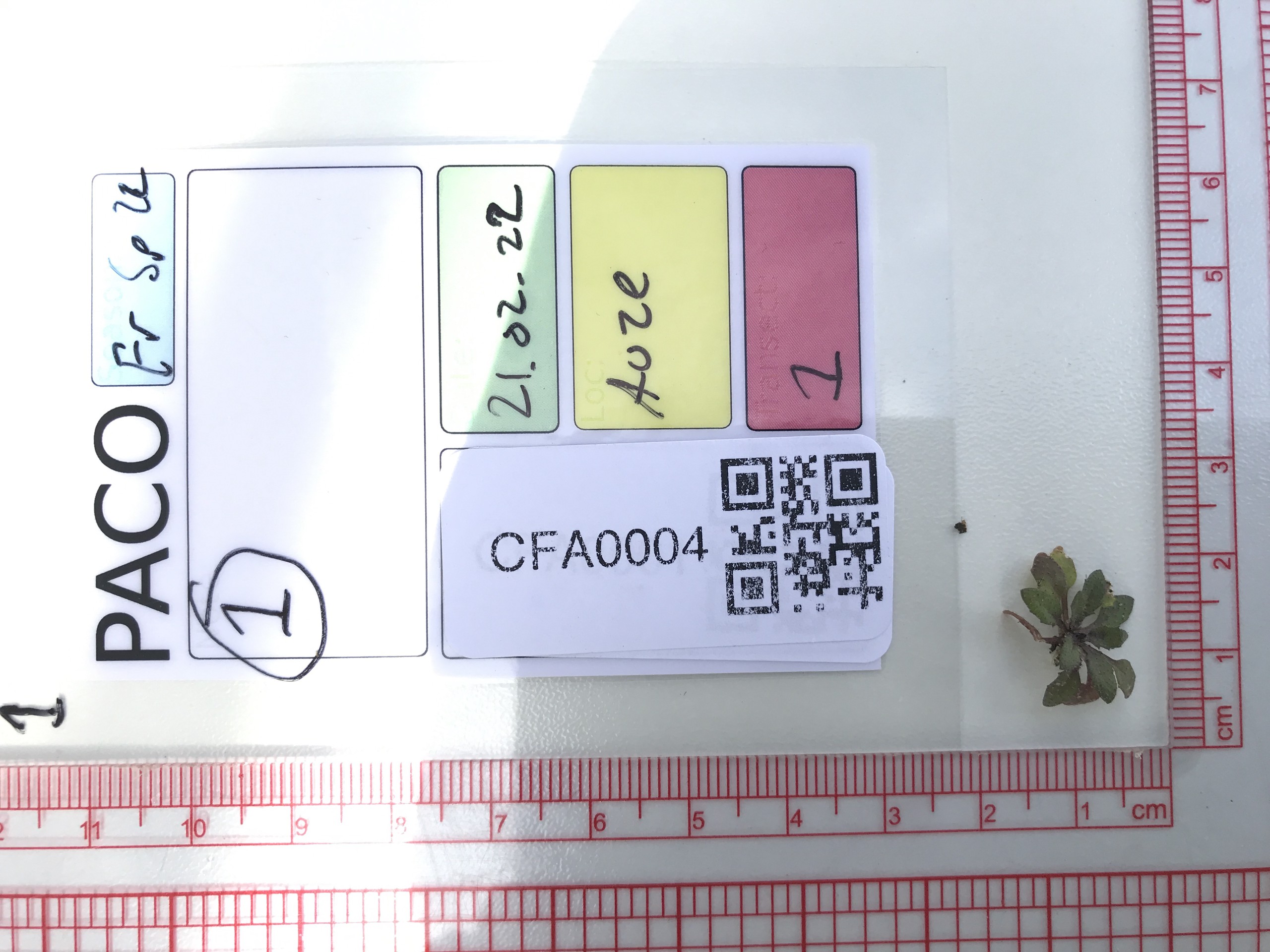





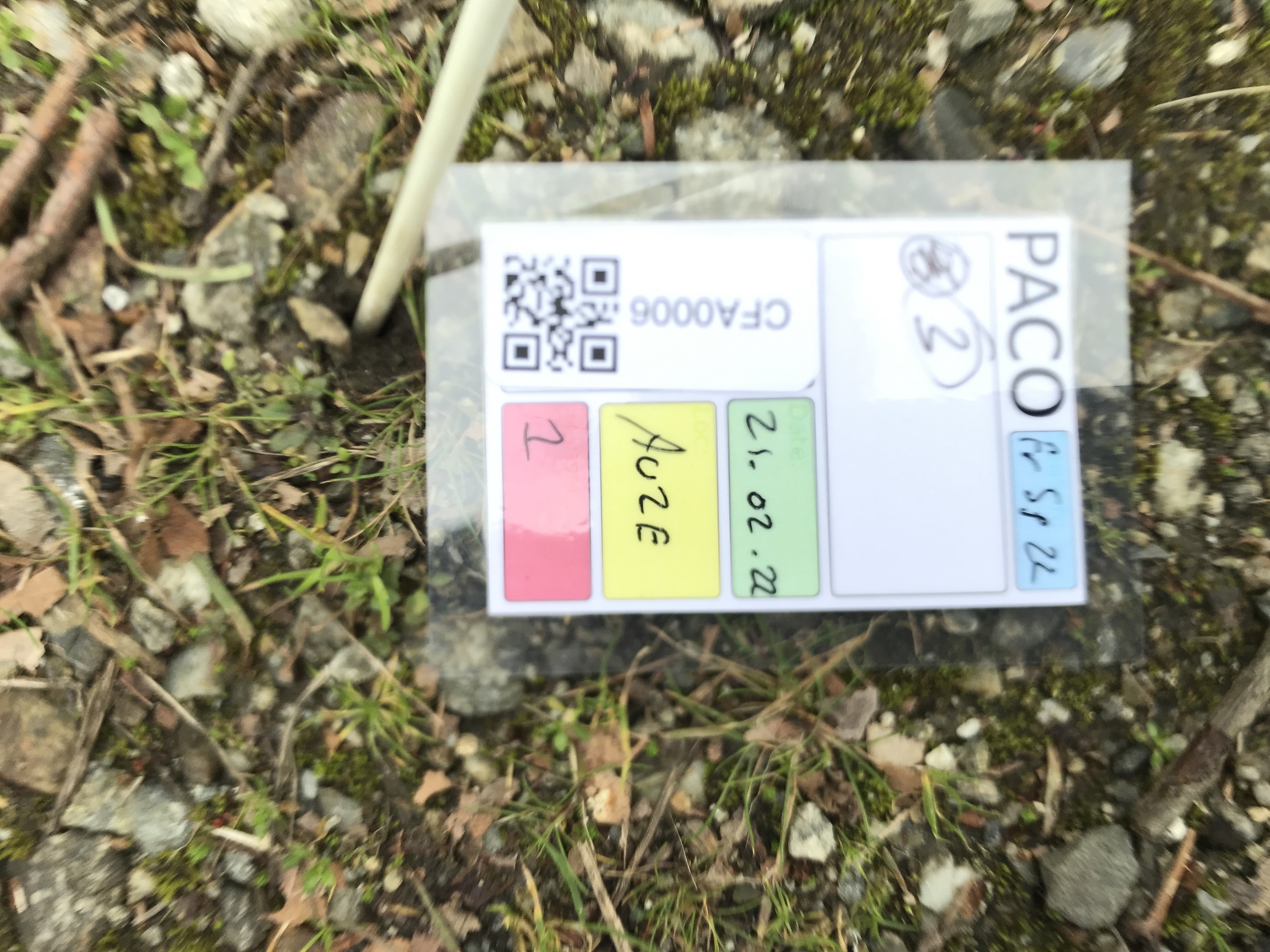
As you can see, these images vary in their quality. It is often the case that in an otherwise useful image, the QR code is either overexposed, out of focus, distorted, or very small. Obviously, that will affect our ability to decode QR codes in these images. So, our goal here is to find a set of simple and automated manipulations we can do in order to improve the rate at which our QR codes are detected.
QR Decoding
We’ll be doing the image processing here in Python, given it has an excellent ecosystem for working with image (meta)data. Specifically, I will be using pyzbar to decode qrcodes within our images. I use mostly PIL/pillow for image IO and manipulation, but also the python OpenCV bindings.
The first experiment will be to see how zbar treats our images before any manipulation. In this post, I will use only snippets of the overall test code, which is available in full at the end of this post, and on github.
def do_one(path):
image = Image.open(path)
codes = pyzbar.decode(image, [pyzbar.ZBarSymbol.QRCODE,])
return list(sorted(d.data.decode('utf8').strip() for d in codes))
This code takes about one second per image, but decodes only about 48% of our test images (a full comparison table is a the end). By eye, we can expect well over half of the above images to be decoded. There are visible barcodes in every single image, and while some are signficantly distorted or defocussed, 48% is a woeful decoding rate.
Pre-processing images
So, what can we do about it? There are several very fancy approaches that try to improve the actual decoding algorthm, either using deep learning image recognition, or hand coded detection of qr code sub-features. But I’m too stupid to understand much of that! So we are left with just simple manipulations. Luckily, they turn out to be quite effective.
A side note here: For clarity and brevity, I elide the actual code used to produce the numbers here, and show just how we would actually use the manipulations in a real decoder. In reality we take the first result that decodes, but in the true testing code (on github), we do ensure that every combination of preprocessor actually gets run. Therefore, while the code below might seem that it biases against later iterations (it does, for effiency), the benchmarking code does run every iteration.
Scaling
def do_one(path):
image = Image.open(path)
x, y = image.size
for scalar in [0.1, 0.2, 0.5, 1]:
image_scaled = image.resize((int(round(x*scalar)), int(round(y*scalar))))
codes = pyzbar.decode(image_scaled, [pyzbar.ZBarSymbol.QRCODE,])
if codes:
return list(sorted(d.data.decode('utf8').strip() for d in codes))
Here, we successively try different downscalings. This is the preprocessing step that has the largest effect. For some magical reason, it seems like scaling down images improves the QR decoding rate! This is somewhat magical to me. I suspect (but haven’t been able to confirm) that the internal algorithm of Zbar expects QRcodes to be an approximate size, and when they are larger, downsizing helps both by reducing the size of the qrcode, and slightly sharpening the whole image.
| Preprocessor | Success | TimeAvg | TimeStDev |
|---|---|---|---|
| scaled 0.2x | 0.6666667 | 0.3012357 | 0.0470919 |
| scaled 0.5x | 0.5925926 | 0.8756736 | 0.0890979 |
| original | 0.4814815 | 1.0055795 | 0.1722981 |
| scaled 0.1x | 0.3333333 | 0.2605467 | 0.0431891 |
Sharpening/Blurring
def do_one(path):
image = Image.open(path)
x, y = image.size
for scalar in [0.1, 0.2, 0.5, 1]:
image_scaled = image.resize((int(round(x*scalar)), int(round(y*scalar))))
for sharpness in [0.1, 0.5, 2]:
image_scaled_sharp = ImageEnhance.Sharpness(image_scaled).enhance(sharpness)
codes = pyzbar.decode(image_scaled_sharp, [pyzbar.ZBarSymbol.QRCODE,])
if codes:
return list(sorted(d.data.decode('utf8').strip() for d in codes))
Here, we combine a sharpen/blur pass with the previous downscaling step. NB: sharpness factors below one indicate blurring, while above one indicate sharpening.
| Preprocessor | Success | TimeAvg | TimeStDev |
|---|---|---|---|
| scaled-0.2_sharpen-0.1 | 0.7037037 | 0.3751884 | 0.0579706 |
| scaled-0.2_sharpen-0.5 | 0.7037037 | 0.3749309 | 0.0577818 |
| scaled-0.2_sharpen-2 | 0.7037037 | 0.3830311 | 0.0590693 |
| scaled-0.5_sharpen-0.5 | 0.7037037 | 1.3453637 | 0.1363030 |
| scaled-0.2 | 0.6666667 | 0.3012357 | 0.0470919 |
| scaled-0.5_sharpen-0.1 | 0.6296296 | 1.3448488 | 0.1345086 |
| scaled-0.5 | 0.5925926 | 0.8756736 | 0.0890979 |
| scaled-1_sharpen-0.1 | 0.5925926 | 2.7943963 | 0.4635821 |
| scaled-1_sharpen-0.5 | 0.5555556 | 2.7921306 | 0.4897494 |
| original | 0.4814815 | 1.0055795 | 0.1722981 |
| scaled-0.5_sharpen-2 | 0.4814815 | 1.3780434 | 0.1509694 |
| scaled-0.1_sharpen-0.5 | 0.4074074 | 0.2806727 | 0.0470607 |
| scaled-0.1 | 0.3333333 | 0.2605467 | 0.0431891 |
| scaled-0.1_sharpen-2 | 0.3333333 | 0.2821618 | 0.0463029 |
| scaled-0.1_sharpen-0.1 | 0.2592593 | 0.2820473 | 0.0451191 |
| scaled-1_sharpen-2 | 0.2222222 | 2.8793262 | 0.5730260 |
We get reliably better results when we apply either sharpening or blurring after downsizing than with downsizing alone. On the whole, it seems that blurring does better, but it does seem to vary by the downscaling factor, and of course it depends on the indiviual image.
Auto-contrast
Here, we apply the autocontrast routine from PILlow to automatically normalise the image histogram (i.e. ensure the image’s contrast is high enough), which helps decoding for low-contrast images.
def do_one(path):
image = Image.open(path)
x, y = image.size
for scalar in [0.1, 0.2, 0.5, 1]:
image_scaled = image.resize((int(round(x*scalar)), int(round(y*scalar))))
image_autocontrast = ImageOps.autocontrast(image_scaled)
codes = pyzbar.decode(image_autocontrast, [pyzbar.ZBarSymbol.QRCODE,])
if codes:
return list(sorted(d.data.decode('utf8').strip() for d in codes))
| Preprocessor | Success | TimeAvg | TimeStDev |
|---|---|---|---|
| scaled-0.2 | 0.6666667 | 0.3012357 | 0.0470919 |
| scaled-0.2_autocontrast | 0.6666667 | 0.3507341 | 0.0540297 |
| scaled-0.5 | 0.5925926 | 0.8756736 | 0.0890979 |
| scaled-0.5_autocontrast | 0.5925926 | 1.1615483 | 0.1287581 |
| original | 0.4814815 | 1.0055795 | 0.1722981 |
| scaled-1_autocontrast | 0.4814815 | 2.0880954 | 0.4108234 |
| scaled-0.1 | 0.3333333 | 0.2605467 | 0.0431891 |
| scaled-0.1_autocontrast | 0.3333333 | 0.2748050 | 0.0450514 |
It seems that the automated contrast adjustment does very little to aid QR code decoding here, and this pattern held for a larger set of images. This also makes sense: any image containing both a plant or some other natural feature (e.g. soil) and a black QR code on white paper is already a relatively high contrast image, especially if the exposure is correct (i.e. exposed for the plant).
Combining all pre-processors
So far, we have seen that there are various treatments we can do to our images to increase the rate of decoding sucess. But in reality, there is no one treatment that will universially increase performace, as the optimal treatment will depend on the individual image. What if we do everything, and either take the union of all results, or the first successful result?
| Preprocessing | Success | TimeAvg | TimeStDev |
|---|---|---|---|
| do-all-the-things | 0.9259259 | 20.8303597 | 3.0229370 |
| take-the-first-thing | 0.9259259 | 14.5268607 | 7.3524694 |
| original | 0.4814815 | 1.0055795 | 0.1722981 |
Wow! Now we’re talking. By iterating over the possible treatments, we find the one(s) that work for each image. This allows us to decode 93% of our test images, which is a massive improvement over the 48% of images that we can decode without any preprocessing. This does obviously take a lot longer to compute, but that is work the computer is doing, not me or you. And, we can reduce this a bit by ordering the preprocessing steps by their likelihood of working and taking the first one that produces results.
Fails
While on the topic, I thought I’d outline a small list of things that didn’t work.
- Automatic brightness/contrast adjustment with CLAHE
- (also, the automatic contrast adjustment from Pillow, as shown above)
- Successively rotating images by ~15 degrees betwen 0 and 90
- Using xzing or other open-source QR decoding libraries (which performed no better than Zbar).
Availablity
This code is available as part of the Natural Variation Toolkit, a set of tools to help manage the sorts of large natural variation collections I work with. I eventually intend to package this QR-decoding subset as a separate python library on PyPI, but for now it’s embedded in the qrmagic CLI/web service (pip install qrmagic). The easiest way to access it is via the free but very slow web portal. If you would like to sort many (~100 or more) images, please use the CLI to do the hard work on your laptop1. You can then use the website to do the curation and generate a script to sort the images. Any questions, email my first name at kdmurray.id.au.
And here is the full code, in case link-rot eats the links to github:
from PIL import Image, ImageOps, ImageEnhance, ImageDraw, ImageFont
from pyzbar.pyzbar import decode, ZBarSymbol
from tqdm import tqdm
import cv2
import numpy as np
import argparse
from sys import stderr
import multiprocessing as mp
from pathlib import Path
from time import time
class KImage(object):
def __init__(self, filename):
self.image = Image.open(filename)
self.filename = Path(filename).name
def write_on_image(image, text):
image = image.copy()
font = ImageFont.load_default()
bottom_margin = 3 # bottom margin for text
text_height = font.getsize(text)[1] + bottom_margin
left, top = (5, image.size[1] - text_height)
text_width = font.getsize(text)[0]
locus = np.asarray(image.crop((left, top, left + text_width, top + text_height)))
meancol = tuple(list(locus.mean(axis=(0,1)).astype(int)))
opposite = (int(locus.mean()) + 96)
if opposite > 255:
opposite = (int(locus.mean()) - 96)
oppositegrey = (opposite, ) * 3
draw = ImageDraw.Draw(image)
draw.rectangle((left-3, top-3, left + text_width + 3, top + text_height + 3),
fill=meancol)
draw.text((left, top), text, fill=oppositegrey, font=font)
return image
def scale_image(image, scalar=None, h=None):
if scalar == 1:
return image
x, y = image.size
if scalar is None:
if h is None:
raise ValueError("give either h or scalar")
scalar = 1 if h > y else h/y
return image.resize((int(round(x*scalar)), int(round(y*scalar))))
def qrdecode(image):
codes = decode(image, [ZBarSymbol.QRCODE,])
return list(sorted(d.data.decode('utf8').strip() for d in codes))
def normalise_CLAHE(image):
cvim = np.array(ImageOps.grayscale(image))
clahe = cv2.createCLAHE()
clahe_im = clahe.apply(cvim)
#cv2.imshow("clahe", clahe_im)
return Image.fromarray(clahe_im)
def rotate(image, rot=30):
return image.copy().rotate(rot, expand=1)
def autocontrast(image):
return ImageOps.autocontrast(image)
def sharpen(image, amount=1):
sharpener = ImageEnhance.Sharpness(image)
return sharpener.enhance(amount)
def do_one(image):
image = KImage(image)
l = time()
def tick():
nonlocal l
n = time()
t = n - l
l = n
return t
union = set()
first = []
first_t = 0
total_t = 0
results = []
for scalar in [0.5, 0.2, 0.1, 1]:
tick()
if scalar != 1:
image_scaled = scale_image(image.image, scalar=scalar)
else:
image_scaled = image.image
res = qrdecode(image_scaled)
st = tick()
union.update(res); total_t += st
if res:
first = res
first_t = total_t
results.append({"file": image.filename,
"what": f"scaled-{scalar}" if scalar != 1 else "original",
"result": res,
"time": st})
for sharpness in [0.1, 0.5, 2]:
tick()
image_scaled_sharp = sharpen(image_scaled, sharpness)
res = qrdecode(image_scaled_sharp)
t = tick()
union.update(res); total_t += st + t
if res:
first = res
first_t = total_t
results.append({"file": image.filename,
"what": f"scaled-{scalar}_sharpen-{sharpness}",
"result": res,
"time": t + st})
tick()
image_scaled_autocontrast = autocontrast(image_scaled)
res = qrdecode(image_scaled_autocontrast)
t = tick()
union.update(res); total_t += st + t
if res:
first = res
first_t = total_t
results.append({"file": image.filename,
"what": f"scaled-{scalar}_autocontrast",
"result": res,
"time": t + st})
results.append({"file": image.filename,
"what": f"do-all-the-things",
"result": list(union),
"time": total_t})
results.append({"file": image.filename,
"what": f"take-the-first-thing",
"result": first,
"time": first_t})
return results
def main():
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--threads", type=int, default=None,
help="Number of CPUs to use for image decoding/scanning")
ap.add_argument("images", nargs="+", help="List of images")
args = ap.parse_args()
pool = mp.Pool(args.threads)
print("Scanner", "Image", "Result", "Time", sep="\t")
for image_results in tqdm(pool.imap(do_one, args.images), unit="images", total=len(args.images)):
for result in image_results:
barcodes = ";".join(sorted(result["result"]))
print(result["what"], result["file"], barcodes, result["time"], sep="\t")
if __name__ == "__main__":
main()
This research was supported by a Marie Skłodowska-Curie Actions fellowship from the European Research Council.
It should “easily” install on any Linux/Mac machine with
pip install qrmagic. See help atqrmagic-detect --help; but in summary something likeqrmagic-detect --threads 8 --output my_images.json my-images/*.jpgshould work. This should be reasonably quick; it will take about 30 minutes to do 1000 images on an average modern laptop. ↩︎